miércoles, 28 de enero de 2009
Querys de Consultas y Reportes de la Aplicacion
Consulta para Validar Usuario
'SELECT CONTRASENA, USUARIO FROM usuarios WHERE USUARIO=\''.$USUARIO.'\'' 
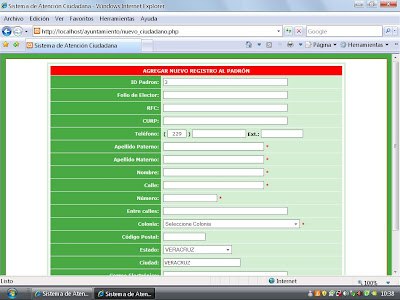
Consulta para Insertar un Nuevo Ciudadano
"INSERT INTO ciudadanos (FOLIO,RFC,CURP,TELEFONO,EXTENSION,APELLIDOPATERNO,APELLIDOMATERNO,NOMBRE,CALLE,NUMERO,ENTRE,COLONIA,CP,ESTADO,CIUDAD,CORREO,ID) VALUES ('$FOLIO','$RFC','$CURP','$TELEFONO','$EXTENSION','$APELLIDOPATERNO','$APELLIDOMATERNO','$NOMBRE','$CALLE','$NUMERO','$ENTRE','$COLONIA','$CP','$ESTADO','$CIUDAD','$CORREO','$ID');"
"INSERT INTO reportes (FOLIO,ID,NOMBRE,TURNADO,ASUNTO,FECHA) VALUES ('$FOLIO','$ID','$NOMBRE','$TURNADO','$ASUNTO','$FECHA');"

Consulta para Actualizar la Contraseña de Usuario
"UPDATE usuarios SET USUARIO='{$_POST['USUARIO']}', CONTRASENA='{$_POST['CONTRASENA2']}' WHERE USUARIO = '$_POST[USUARIO]'"

"SELECT * FROM ciudadanos WHERE CURP = $_POST[CURP]"

Consulta para Autoincrementar el Folio de los Reportes
"SELECT MAX(FOLIO) as maximo FROM $tabla"
Reporte de Ciudadano que su Folio de Elector este Registrado
"SELECT * FROM ciudadanos WHERE FOLIO = $_POST[FOLIO]"
Reporte de Reportes por Folio de Reporte
"SELECT * FROM reportes WHERE FOLIO = $_POST[FOLIO]"
Consulta para Insertar un Nuevo Usuario
"INSERT INTO usuarios (USUARIO,CONTRASENA,NOMBRE,AREA) VALUES ('$USUARIO','$CONTRASENA','$NOMBRE','$AREA');"

Reporte de Ciudadano que su RFC este Registrado
"SELECT * FROM ciudadanos WHERE RFC = $_POST[RFC]"
Reporte de Ciudadano que su Telefono este Registrado
"SELECT * FROM ciudadanos WHERE TELEFONO = $_POST[TELEFONO]"








_p01.JPG)
_p02.JPG)